2. 8. 2022
4 min read
Reoccurring conflicts after git squash merge
In many projects, branches are being merged with a squash option. This can be helpful to keep the commit history clean. But we need to be mindful when merging a branch that is a parent to some other branch.
Tomáš Ondrej
Software Engineer

Example
Let’s take the following git repository structure

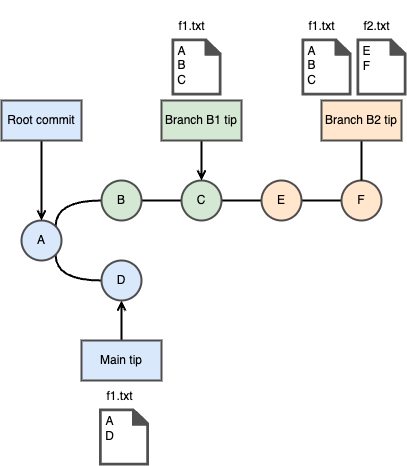
There are 3 branches: main (blue), B1 (green), and B2 (orange). B2 has been created from B1. Letters A, …, F represent each commit. Rectangles next to the branch tips are visualizing a file state at that specific commit.
Now, the work on branch B1 is done and we want to squash merge it with the main branch.
$ git checkout main$ git merge --squash b1Auto-merging f1CONFLICT (content): Merge conflict in f1.txtSquash commit -- not updating HEADAutomatic merge failed; fix conflicts and then commit the result.Git could not merge the branch automatically because there’s a conflict in file f1.txt which was modified both in main and B1. We resolve the conflict and finish the merge. After that we get the following structure:

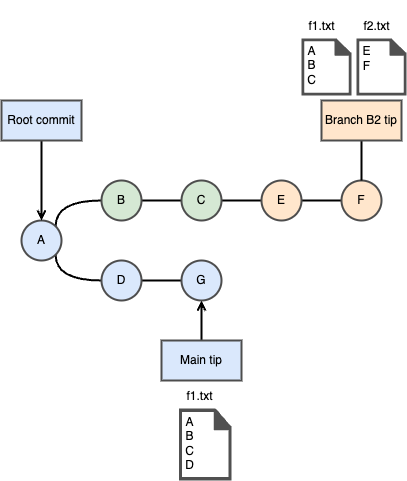
There are 2 branches left - main and B2. Now the work in B2 is finished and we want to merge it into the main branch so we follow the same procedure:
$ git checkout main$ git merge --squash b2Auto-merging f1CONFLICT (content): Merge conflict in f1.txtAutomatic merge failed; fix conflicts and then commit the result.The auto-merge could not happen because of the conflict in the file f1.txt. Why? The only change we introduced in branch B2 was creating a new file f2.txt. Why do we have to resolve the same conflict that has already been resolved when merging B1 into main? To find out why let’s take a look at how git merge works.
There are 2 different types of merges: three-way and fast forward. In our example, git will use three-way merge because there isn’t a linear path to the target branch.
Linear vs non-linear path from B1 to main

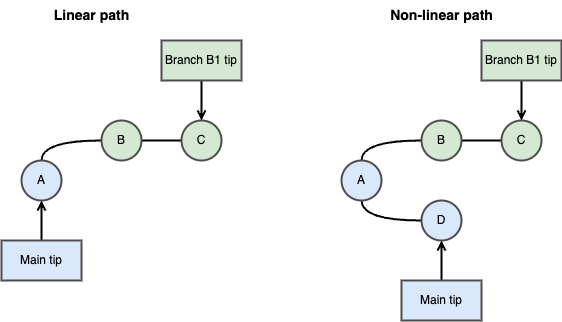
Linear path: there’s no commit after B1 has been created, so we can just fast-forward the main tip to point to the commit B1.
Non-linear path: there’s a commit after B1 has been created, so git will use a three-way merge.
Now that we know what merge strategy has been used, let’s take a closer look at the three-way merge.
Three-way merge
When we try to merge branch B1 into main, git will backtrack both branches to find a shared commit that exists in both of them. In our case, it’s commit A. Such commit is called a merge-base.
The merge-base can be found with git merge-base <commit> <commit> command.
$ git log --graph --oneline --all # print commit graph
* ccfe592 (b1) C* 0e14aa5 B| * 17866d5 (HEAD -> main) D|/* c4049e1 A
$ git merge-base main b1 # We can also use branch names because a branch name is a reference to a commitc4049e14c05ba0a88c13ef062eab18280efb1d02
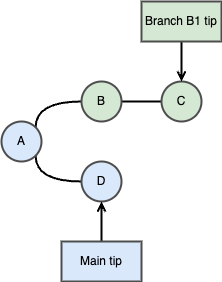
Once the merge-base is found (commit A), git needs to find what has been changed on main and B1 separately. It starts by extracting the merge-base commit itself to a temporary area. Now that Git has the merge-base extracted, git diff will find what has changed on the main branch between snapshot D and A. That’s the first change-set.
Git now has to run a second git diff to find what has changed on B1: the difference between snapshot C and A.
Then, it combines these two sets of changes and applies them to what’s in snapshot A (the merge-base), and makes a new commit from the result. After that, the merge is completed.
A new merge-base prevents recurring conflicts
Now that we know how git finds changes in a three-way merge, let’s compare merge-base after a squash merge and after a merge commit. We will print a commit graph for each merge type.
# commit graph after squash # commit graph after merging b1# merging b1 # using a merge commit
* c713bc7 (HEAD -> main) G |\* 5673bd4 (HEAD -> main) G * | 17866d5 D* 17866d5 D | | * 1e9afd8 (b2) F| * 1e9afd8 (b2) F | | * 0960141 E| * 0960141 E | |/| * ccfe592 (b1) C | * ccfe592 (b1) C <-- merge-base| * 0e14aa5 B | * 0e14aa5 B|/ |/* c4049e1 A <-- merge-base * c4049e1 A
$ git merge-base main b2 $ git merge-base main b2c4049e14c05ba0a88c13ef062eab18280... ccfe59230f2e5c275ab9c095b1b77d7e...We see that the merge-base has not been changed after the squash merge. When doing a squash merge, we take all the commits of B1 and squash them to a new commit (G) which will be applied to the main branch. This commit has no common history with the branch B2. So during the merge of B2, the merge-base will be the same as for B1 - commit A.
If we execute git diff between commit A and commit F, we see changes to file f1.txt. If we execute git diff for the commits from the main branch, namely A and G, there are also changes to file f1.txt, which means there is a conflict.
That’s the reason why we had to resolve the conflict for the file which hasn’t even been touched in the branch. Because there wasn’t a new merge base that would exclude the already merged changes from the merge execution.
On the other hand, an ordinary merge will preserve the commit history via a merge commit. It means that the history of the branch B1 is now part of main. When we try to merge B2, the merge-base will be commit C because it is part of both branches. If we compare commit C and F, the only change is a new file f2.txt
$ git diff ccfe592 1e9afd8 # Find diff between commits C and Fdiff --git a/f2 b/f2new file mode 100644 # The only change is a new file f2.txtindex 0000000..4bf0f1f--- /dev/null+++ b/f2.txt@@ -0,0 +1,2 @@+E+FSummary
Git merges in two ways: fast-forward and three-way. Git uses the three-way merge if a commit graph is not linear. The three-way merge uses a merge base (a common ancestor) to calculate changes for each of the 2 branches we want to merge together. If we use git merge —squash, git rebase or git cherry-pick, the commit history of a source branch will not be kept.