19. 1. 2024
12 min read
Autoencoders explored: The what, why, and how
Exploring autoencoder neural networks? They are versatile technologies capable of extracting meaningful information from unlabeled data through clever architectural choices. And this blog simplifies it all. Learn why they matter, how they compress information, and where they spot irregularities.
Erik Kandalík
Data Scientist & Software Engineer


Motivation
Since I expect you to know nothing about autoencoders, let's approach them as a black box.
Autoencoders are quite an easy and impressive idea used across the field of machine learning. It was originally used to reduce the dimensions of data but has recently found its way into almost every possible application.
Dimensionality reduction is simply speaking the process of somehow making data smaller but keeping as much information as possible. We try to do it because it is usually much easier to work with smaller data structures, and we improve the performance of the computation.
One of the possible applications is anomaly or outlier detection, a process where a trained autoencoder network can distinguish if an anomaly has occurred in your data. The most naive use case would be a monitoring system for software products, but the same idea can be applied even outside of the software engineering domain. For example, you can monitor real-world machinery, like wind turbines, and check if they perform as expected based on the measured data and capture anomalous behavior without the need to create specialized metrics and thresholds.
Another quite interesting area is domain-specific data compression. In such cases, the autoencoders are trained on the set of your domain data (for example pictures of butterflies) and can encode the data into smaller formats. This practice should be viewed as a lossy compression, but the fact that it can be domain-specific means, that the compression ratio can be quite high.
Data denoising is another interesting field where the autoencoder can be used to “clean” the data from noise. In this process, the autoencoder neural network can be trained to transform noisy data (for example butterfly images with burned-out pixels) into clear data without the noise.
Probably the most versatile application is the possibility to extract patterns or features from the data itself without the need to have labels associated with individual data points. That means that thanks to the autoencoder neural network you can extract meaningful information without the need of tedious work of labeling every single data point.
The last point is especially useful in the real world, where we almost always have more unlabeled data than the other way around. This is why autoencoder neural networks are so versatile and can be used in different areas of interest.
Okay so we know, at least a little bit, why are autoencoders important, let’s try to answer what are they in the first place.
What are autoencoders? (Simple)
An autoencoder is a neural network that is trained to attempt to copy its input to its output.
This is the simplest possible explanation. Why would you want to train a neural network to produce the same output as the provided input? Because by doing so, the middle layers of the neural network can learn some good representation of your data, that can be used in downstream tasks. The data representation from the middle layers is what we are interested in.
What are autoencoders? (Intermediate)
Okay, let’s expand this a little. The premise stays the same but we will make a few things more clear. One of the simplest possible autoencoder neural network architectures looks like this:

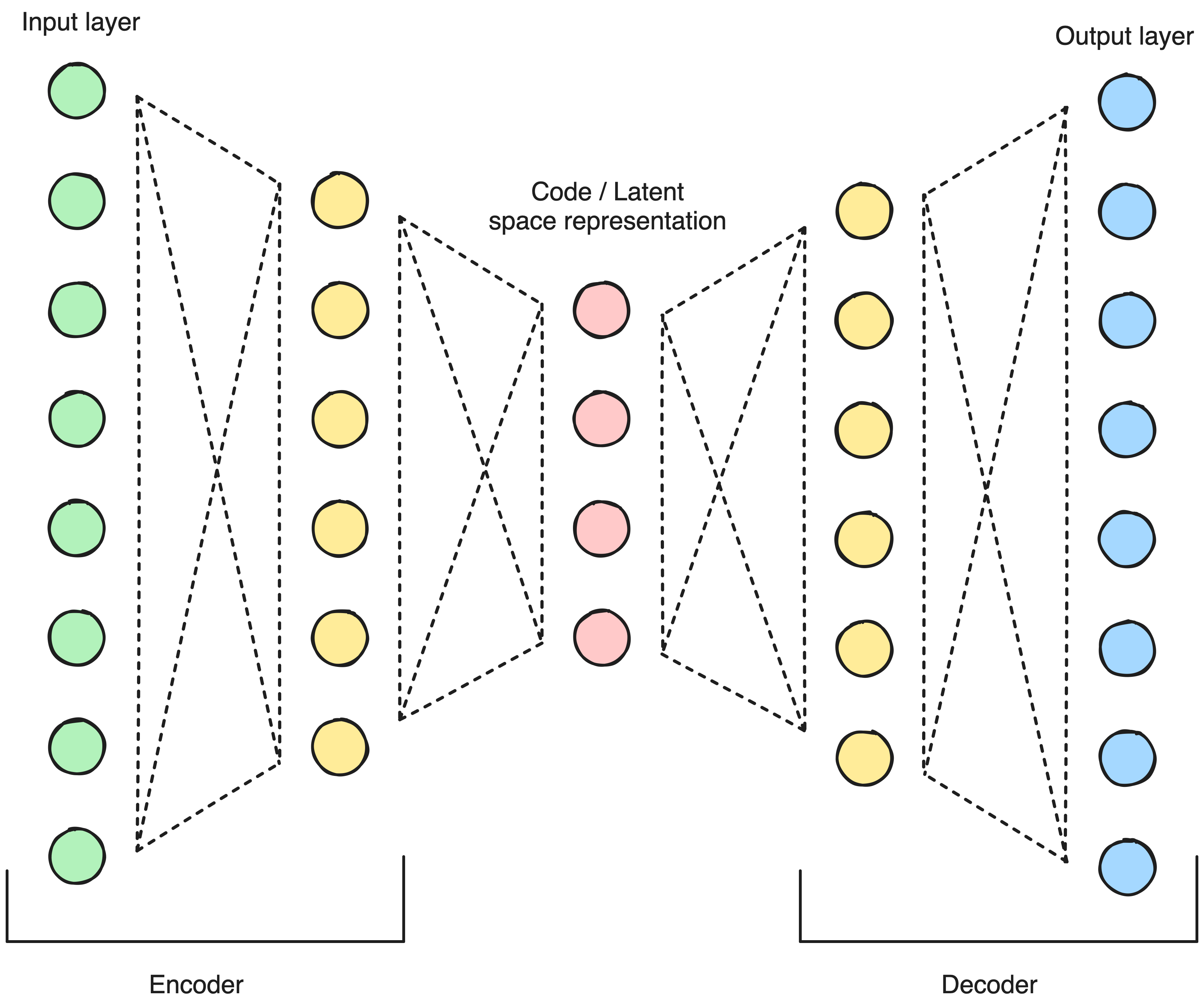
The left part of the neural network is called the encoder and is responsible for transforming the input data into already mentioned compressed representation. The compressed representation is also referred to as code, or latent-space representation, which means a data representation containing the most important features.
Latent-space representation is a representation of data usually in numerical form that captures the essence, the most important characteristics or patterns of the data are usually in a smaller format. It can be also referred to as a more familiar term - embedding space - but since this term is usually connected to the NLP I don’t want to cause more confusion than necessary.
The right part of the neural network is called the decoder. As you can see, it expands from the middle layer of the network which has a reduced number of neurons into the output layer. And since we need to reconstruct the data in the output layer, it has the same amount of neurons as the input layer. The decoder is responsible for reconstructing the original data from the compressed representation or latent-space representation.
The interesting part is that you can separate the encoder and decoder into two separate neural networks. In this case, the encoder can be used as a domain-specific compressing algorithm, and the decoder as a domain-specific decompressing algorithm. This means that you can encode your data into smaller dimensions, send it over the internet, and on the other side of the world, decompress it with the decoder. You need to send the decoder to the other party first of course.
What is even more interesting are the properties of the latent-space representation from the middle layer of the neural network. As we have already mentioned, this is something we are usually most interested in. Ideally, the latent-space representation contains the most important characteristics of our data. We might not know what the features are. For example, in the case of our butterflies dataset, the features might be things like the color of the wing or length of the body, etc. We let the neural network figure out what the most important features are by creating constraints on the number of neurons in the middle of the neural network.
You can intuitively think about it this way: our objective is to train the neural network to produce the same output as the input. Let’s imagine we can compare input and output and say how similar or different they are. By limiting the number of neurons in the middle layer, we are forcing the neural network to forget some information because there is not enough “space” to store everything. And since we penalize the neural network during training for output that is too different from the input, the neural network needs to figure out how to forget only the least important information to produce the output that is as similar as possible to the input. After we finish the training we are left with latent-space representation with the most important feature of our data.
What are autoencoders? (formal)
Okay as of now, you might have a brief understanding of what the autoencoders are conceptually. In this section, we will add a little bit of formality to the description, because creating understanding at a lower level enables us to reason about different approaches to how to create an autoencoder neural network. As you will see there are technically different kinds of autoencoders. We will present the most important one that differs from an architecture standpoint. Hopefully, this will lead to a better understanding.
Let's start with the formal definition. We will add a little mathematics from now on but don’t feel overwhelmed. You can skip the equations and jump right into the description. Without further ado, let’s define the autoencoder more formally.
As we already mentioned autoencoder neural network can be formally divided into two main parts: encoder and decoder, where the formal definition for the encoder process can be defined as

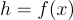
where h represents the output of the encoder-latent-space representation, x is the input of the autoencoder neural network, and f is the encoder function.
The decoding process can be described as

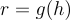
where r is the output of the decoding process, g is the decoder function, and h is the latent-space representation. The decoding process can be also rewritten to the form of r = g(f(x))
The formal representation of the data flow is displayed in the graph below:


Based on the definition above, you might assume that the training objective would involve learning functions f and g such that

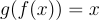
However, this identity function would not be very useful. It is not useful because in practice this usually means that the neural network has too much capacity and it is not learning the underlying features but simply remembering how to reconstruct the input to output.
Simply speaking we need to ensure that the network doesn’t have enough capacity to just remember which output belongs to which input. In the scenario when the network has too much capacity, you can imagine that the network can learn to assign indexes to each input and reproduce output solely from them. Having a pseudo lookup table is not very useful, since our primary objective is to extract underlying features.
For that reason, our goal is to restrict the training process in different ways so that the autoencoder cannot learn the identity function perfectly. In other words, we want just to approximate the identity function. The reason behind this approach is that by imposing such limitations on the neural network, we force it to prioritize and learn the important data features as a byproduct of the training process.
When it comes to different restraining processes during training, the simplest one, as described at the beginning of the blog post, is to constrain the dimension of h (latent-space representation) so that h < x. These kinds of autoencoders are called undercomplete autoencoders. In such a neural network, the architecture design itself serves as the constraining factor, and in theory, we don't need any additional regularizations. We need to minimize the loss of function

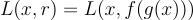
where we penalize the dissimilarity between x (input) and r (output). During this process, the restricted architecture forces the autoencoder model to extract the most important features to reconstruct them. We should not be able to train the model to a perfect identity function, thanks to which we might expect the latent-space representation to contain a meaningful, most important feature of our data.
Another possibility of constraining the learning process is with a different kind of regularization mechanism. There are multiple kinds but they share the common name of regularized autoencoders. The main motivation why you should care about them is the fact that the previously mentioned under-complete autoencoders might be quite hard to “tune.” You see, in the case of the undercomplete autoencoders, it is hard to ensure that the capacity of the network is optimal. Even though we restrict the number of neurons in the middle layers of the neural network, the capacity can be still high enough for the network to just remember how to assign the correct output to the corresponding input. And we don’t want that because that would mean that the latent-space representation doesn’t capture the most important features. The idea behind the regularized autoencoders is to utilize different mathematical tools or strategies during the training process such that we can introduce restrictions indirectly (not only by augmenting the dimensions of neural network layers). In theory, these techniques can be used even in autoencoder neural networks where the dimension of the latent representation h is greater than input x.
The regularized autoencoders consist of three main subcategories:
sparse autoencoders
denoising autoencoders
autoencoders regularized by penalizing derivatives
All the subcategories use different mathematical tools to introduce restrictions. The sparse autoencoders and autoencoders regularized by penalizing derivatives are augmenting the loss function of the training process into the form

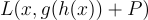
where P introduces some form of penalty on the output of the decoding process r or, in the case of autoencoders regularized by penalizing derivatives, also on the derivatives of x. What it means is that P is a function of h and possibly a derivative of x, which increases the output of the loss function based on that input. The precise implementation of the function P is not so important in the context. The main idea is that the training process is constrained by updating the loss function in a way so that the network is unable to learn the identity function perfectly and enforce the neural network to capture the most important data feature, which is exactly what we want.
The denoising autoencoders, on the other hand, try to restrict the training process by incorporating noise into the input and forcing the autoencoder network to do something useful from the very beginning. This kind of autoencoder is the exception where the output from the decoder is what we are interested in. The formal definition of such a process is to introduce the corrupting process of input described as

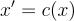
where x is the input, c is the corrupting function, and x’ is the corrupted version of the input. The loss function then looks like

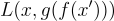
This way, the neural network is forced to learn how to undo the corruption introduced to the input. It has been shown that this process indirectly causes the autoencoder to learn meaningful and useful representations of data as a byproduct of minimizing the reconstruction error. Let’s take the example of butterflies from the previous paragraph. The idea is very similar, but we introduce the noise into the images. We will burn out some pixels of the butterflies first and try to train the neural network to reconstruct the original image. Even in case the network has too much capacity, it is very unlikely that the neural network will be able to reconstruct the perfect image of a butterfly (with a loss equal to zero), since we are reducing information with a corruption process even before we pass it into the neural network.
Summary
The autoencoder neural networks are trained to attempt to copy its input to its output. They are versatile technologies capable of extracting meaningful information from unlabeled data with clever architectural choices. Several types differ by the means of restrictions provisioned on neural networks to eliminate the possibility of neural networks learning identity function perfectly. What we are usually interested in is the latent-space representation obtained from the middle layer of the neural network, which is useful for downstream tasks like classification.
You might
also like